
 by Mikito
by Mikito
【论文阅读】Rethinking Attribute Representation and Injection for Sentiment Classification (EMNLP 2019)
Task
Sentiment Classification with attributes(user, product)
Motivation
在情感分析中,一些文本自带的属性信息,如user(文本是谁写的)、product(文本是关于什么产品的)信息通常会对情感分析有一定 的帮助,所以最近的一些工作都会用他们来提升模型性能和增加可解释性。
但是,现有的很多方法都是使用注意力机制来进行外部信息的融合,具体的计算公式如下:
$$ a = softmax(v^Te) $$
$$ e = tanh(Wh+W_uu+W_pp+b) = tanh(Wh+b_u+b_p+b) = tanh(Wh+b^{'}) $$
从这个公式可以看出,用这种方式加入属性信息,其实是加了一个额外的bias,所以会有如下两个问题:
- 以额外bias的方式加入属性信息,bias仅与属性有关,忽略了属性和文本之间的关系。
- 只将属性信息用在attention weight计算中,利用不充分。
所以在attention中以Bias的方式加入属性信息并不是最理想的方法。
这篇论文从以下两个方面对属性融合方式进行分析: - 属性应该以什么样的形式加入?
- 属性应该在哪个位置加入?
Base Model
为了探究属性融合方法及位置的影响,这里选了一个最简单的模型作为基础模型。
输入:文本x
输出:情感y
模型结构:
- Word embedding:对word embedding接一个非线性层
- LSTM
- Attention
- Classifier
How: Attribute Representation
可以看到,在这四个部分(参见论文中公式),有一个相似的非线性函数:
$$g(f(x))=g(Wx+b)$$
那么,在不改变原有模型的基础上,属性加入的形式有两种:
- 权重W
- 偏置b
Bias-based
现在的模型大多以bias的方式加入信息,但是这样忽略了文本和属性的关系。
$$b^{'} = W_uu+W_pp+b$$
Matrix-based
基于weight matrix的方法想要从属性中学习得到weight矩阵。
$$ w^{'} = W_c[u;p] + b_c $$
$$ W^{'} = reshape(w^{'}, (D_1 \times D_2)) $$
$$ f(x,u,p) = W^{'}x + b $$
但是这样会使得参数量很大,约有$|U| * |P| * D_1 * D_2$。
CHIM-based
本文提出了一种替代的Chunk-wise Importance Matrix,以学习weight importance替代学习weight,并用重复的chunk(大小为($D_1/C_1,D_2/C_2$))构建weight importance矩阵。
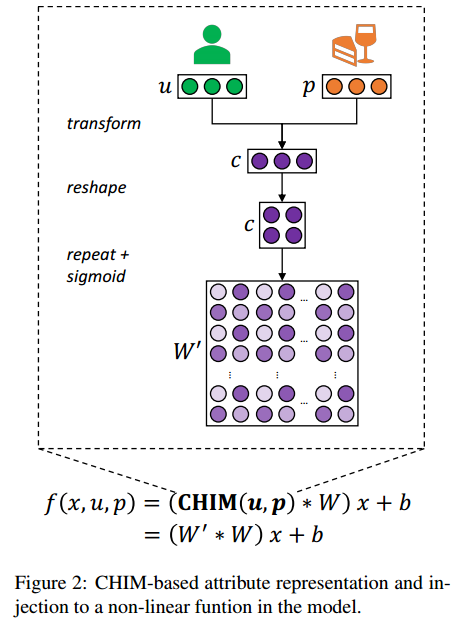
这种方法可以有效降低参数数目,并且保持模型性能。
Where: Attribute Injection
In the word embedding
在word embedding进行attribute融入会影响一个word的表示,而这个影响和上下文是独立的。假如已经学习到一个用户使用tasty表示一个一般的情感强度(3星),用delicious表示强烈的情感(5星),那么在word embedding加入属性信息会使得它们的表示不相同(尽管它们是近义词)。
In the BiLSTM encoder
在BiLSTM进行attribute融入会使得对word的表示的影响是上下文是相关的。假如已经学习到一个用户喜欢甜品但是无糖饮品,那么对于文本“the cake was sweet”会给出一个正向的信号,对于“the drink was sweet”会给出一个负向的信号,而不单是以“sweet”决定。
In the attention mechanism
在attention进行attribute融入是会使得改变句子中词的attention权重,但是这无法反映用户针对这些词的情感偏向性。
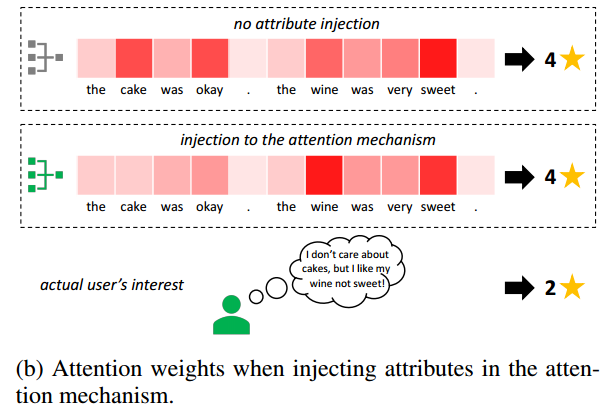
In the logistic classifier
只根据文本的总体表示进行情感bias的影响。
Experiments
- Sentiment Classification
- Attribute Transfer