
•
 by Mikito
by Mikito
by Mikito
【论文阅读】Explainable and Discourse Topic-aware Neural Language Understanding (ICML 2020)
Task
Language modelling,计算一个序列的概率,这篇论文的一个任务就是预测下一个词。
Motivation
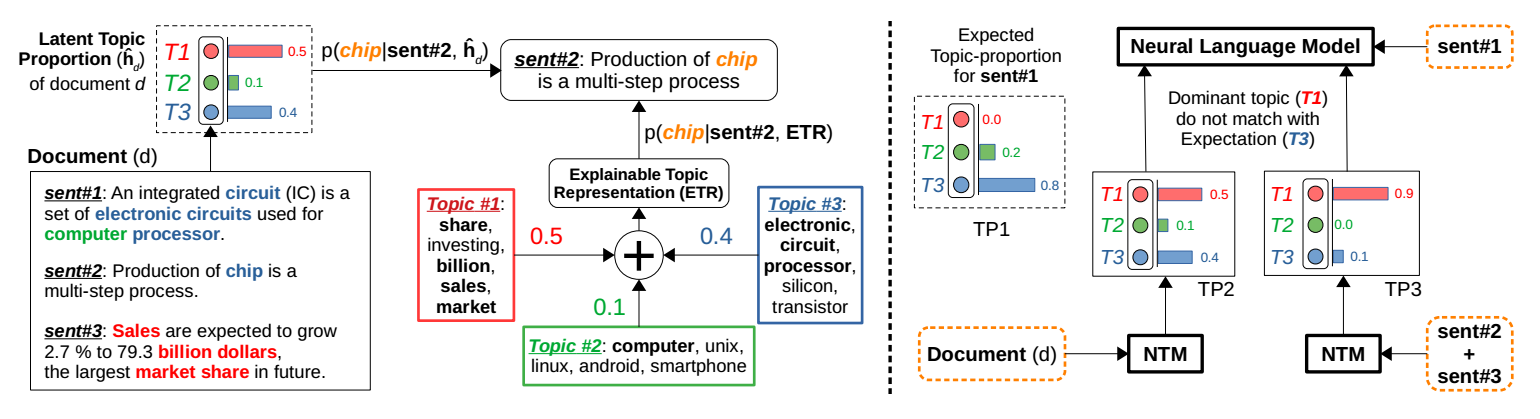
- LM一般做的是sentence-level的,但是有的时候全文的信息对当前句子的预测也很重要。如果输入的是document,做document-level LM,由于LM一般是RNN的总是,对于超过200个词的文本仍然存在之前信息遗忘的现象,所以就有人提出向LM里加入TM的信息来加入全文的信息。之前的方法一般加入的都是文本的topic distribution,忽略了topic的解释性表示,所以这篇论文提出加入两种topic信息:Latent Topic Proportion和Explainable Topic Representation。
- 对于某个句子来说,它的topic distribution可能和文档的有一些区别,所以也要考虑这个句子的topic distribution。
Method
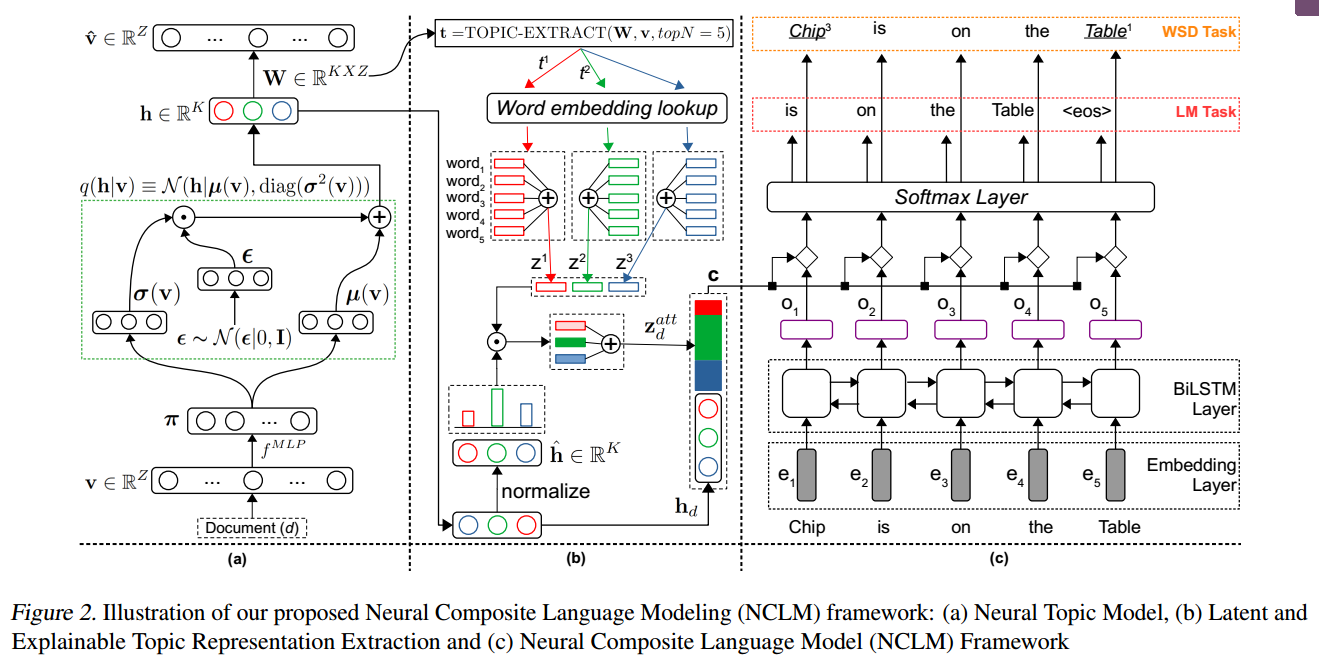
- Latent Topic Proportion:NTM的topic distribution
- Explainable Topic Representation: 对于每个topic,取其中TopK的单词的embedding的平均作为表示。然后使用Latent Topic Proportion作为权重,进行加权求和。
- NLM:LSTM对文本进行编码,然后将Latent Topic Proportion和Explainable Topic Representation进行级联,与单词表示混合。再进行最终的prediction。
- 为了考虑sentence信息,可以将sentence作为输入同样得到Latent Topic Proportion和Explainable Topic Representation,并和文本得到的Latent Topic Proportion和Explainable Topic Representation进行concat。
Experiments
在多个Task上(Language Modeling、Topic Modeling、Text Classification、Information Retrieval、Word Sense Disambiguation),都具有良好的效果。