
•
 by Mikito
by Mikito
by Mikito
【论文阅读】Aspect Sentiment Classification with Document-level Sentiment Preference Modeling (ACL 2020)
Task
Aspect Sentiment Classification (ASC)
例子:The restaurant has quite low price but the food tastes not good
Price:positive
Food:negative
Motivation
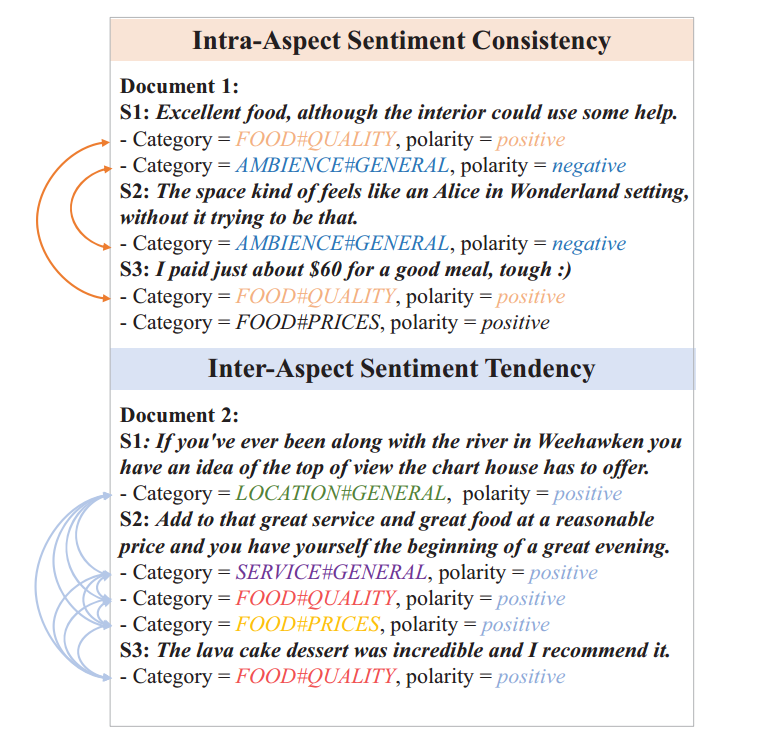
通常的方法都是sentence-level的,即针对一个sentence,每次分析一个aspect的情感,各个sentence之间是互相独立的。但是实际上,sentence是document的一部分,仅考虑sentence-level会丢失部分信息,所以应该考虑document-level的情感。主要包括以下两个方面:
- contextual sentiment consistency (intra-aspect consistency): 即对于一个文档,其中相同aspect的情感极性应该是一致的。
- contextual sentiment tendency (inter-aspect tendency): 即在同一个文档,各个aspect的情感极性应该是相似的。
Method
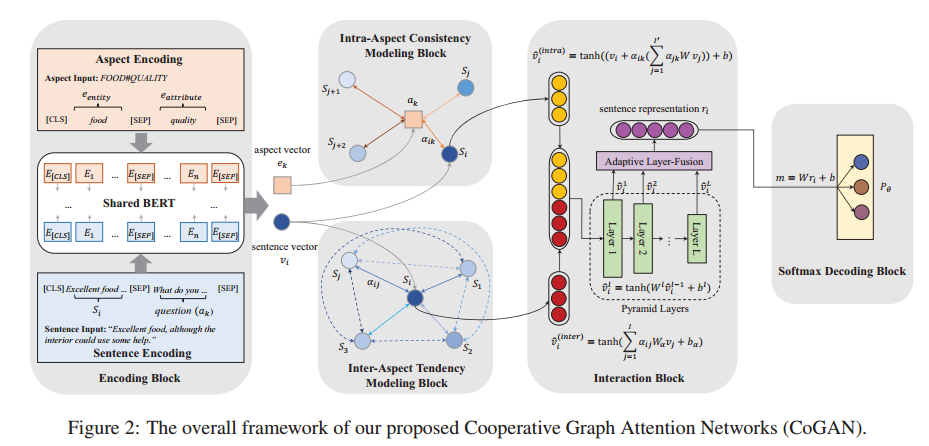
- Encoding Block
用bert对sentence和aspect进行编码。 - Intra-Aspect Consistency Modeling Block
- 建立GAN(二分图):顶点是sentence+aspect,边是sentence和aspect的共现关系。
- 对于第k个aspect顶点 $a_k$,计算出每一个与它关联的sentence的权重。
$$\alpha_{ik} = \frac{exp(f(w^T[W_vv_i;W_ee_k]))}{\sum_{t=1}^{I'}{exp(f(w^T[W_vv_t;W_ee_k]))}}$$ - 然后根据权重进行加权求和,得到第k个aspect顶点 a_k的一个向量表示,再和原来的句子表示相加得到aspect-related sentence representation。
$$\hat{v}_i^{(intra)} = tanh((v_i+\alpha_{ik}(\sum_{j=1}^{I'}{\alpha_{jk}Wv_j}))+b)$$
- Inter-Aspect Tendency Modeling Block
- 建立GAN(无向图):顶点是sentence,边是sentence和sentence的共现关系(全连接)。
- 对于第i个sentence顶点 $s_i$,计算出每一个与它关联的sentence $s_j$的权重。
$$\alpha_{ij} = \frac{exp(f(w^T[W_1v_i;W_2v_j]))}{\sum_{t=1}^{I'}{exp(f(w^T[W_1v_i;W_2v_t]))}}$$ - 然后根据权重进行加权求和,得到i个sentence顶点 s_i的一个向量表示。
$$\hat{v}_i^{(inter)} = tanh(\sum_{j=1}^{I}{\alpha_{ij}W_{\alpha}v_j}+b_{\alpha})$$
- Interaction Block
- Pyramid Layers:由于级联并不是一种很好的特征融合方法,所以这里采用了金字塔式的特征融合方法得到表示,就是将下一层的维度降到上一层的一半。
- Adaptive Layer-Fusion:为了更好的将多层特征融合起来,使用自适应的多层融合,即对每层设定不同的权重(可学习),然后进行级联。
- Softmax Decoding Block
使用一个softmax分类器(3类)得到最终的分布,并用交叉熵进行训练。
Experiment
包括和ASC方法对比、Case Study、假设验证和错误分析四个部分,实验比较充分。
感想
- 论文的Motivation很重要,我觉得像这种一致性或者整体倾向性可以在很多地方换个其他的名字,比如之前Personalized SA中产品整体的倾向和用户的倾向等。
- 本篇论文的很多模块是现有模块,然后对他们进行了组装。但是对于有一些地方,比如金字塔混合,就比一般的级联或者MLP好一些。可以学习一下。