
•
 by Mikito
by Mikito
by Mikito
【论文阅读】Knowledge-Enriched Transformer for Emotion Detection in Textual Conversations (EMNLP 2019)
Motivation
人们的对话中通常包含着很多情感信息。但是人们通常在对对话进行情感分析的时候具有如下两个特点:
- 考虑上下文的信息。
- 人们本身具有一定的commonsense knowledge,利用commonsense knowledge进行对话分析。
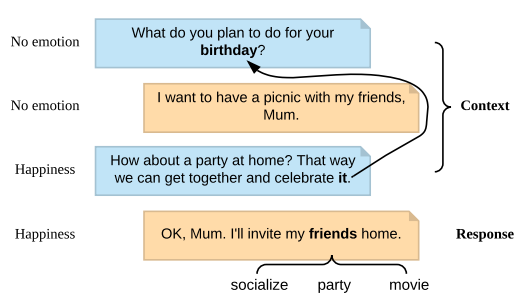
所以针对如上两个特点,本文提出了Knowledge-Enriched Transformer(KET)模型,该模型使用了层次的self-attention来得到文档的上下文关系,而且与之前方法不同,context和response分别作为encoder和decoder(bert 是将context和response进行concat,然后只用了encoder进行训练)。并且通过一个context-aware affective graph attention来加入commonsense knowledge。
Method
Transformer —— Attention is All You Need(https://arxiv.org/abs/1706.03762):
Transformer的motivation之一是减少序列的计算开销,而且在一些情况下确实也比rnn、cnn好很多。
- 由于句子在encoder部分时不是序列性的,所以加入了position embedding表示当前词的位置信息。
- Multi-head attention是多个Scaled Dot-Product Attention叠加。
- Feed Forward:全连接网络,包括两个线性变换和一个ReLU激活输出。
- Decoder部分相较于encoder多了一个attention,这个attention将encoder的输出也作为一个输入。
KET model
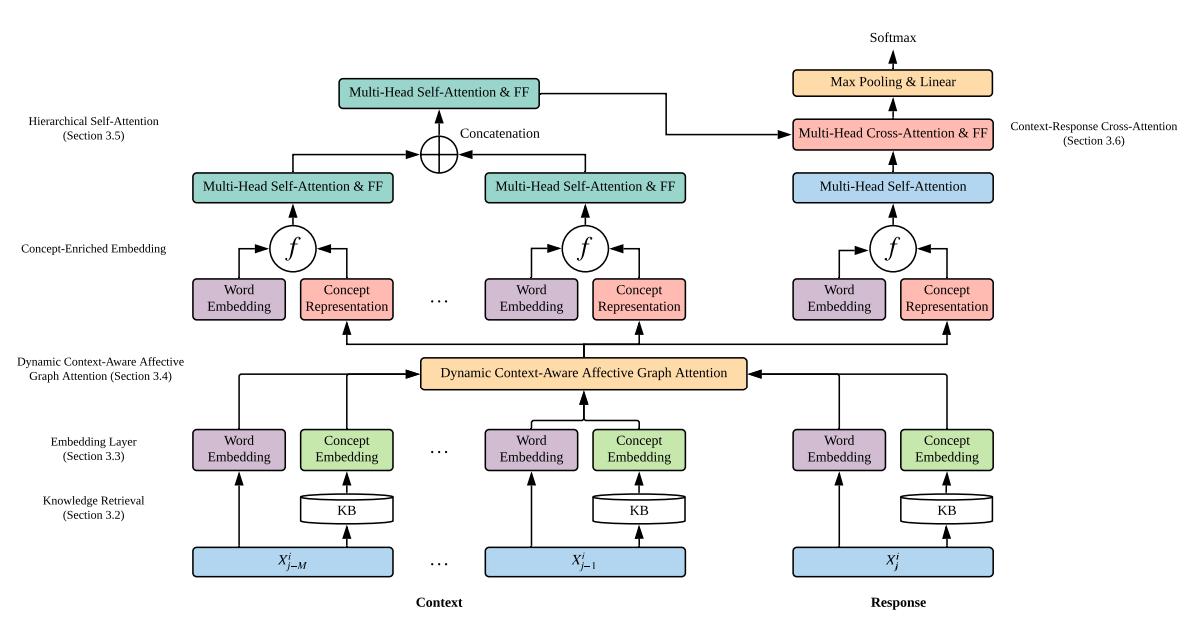
- 知识库检索:
使用的额外知识:
- Commonsense knowledge base ConceptNet (Speer et al., 2017):多语言的数据库,数据以三元组的形式存储<concept1, relation, concept2>,并且对这个三元组具有一个 [1, 10] 区间内的置信度打分。
- Emotion lexicon NRC VAD (Mohammad, 2018a):包括2w个左右的英语单词,每个词对应一个三元组,<valence (negative-positive), arousal (calm-excited), and dominance (submissive-dominant)>。
针对每个非停用词词,从数据库中抽取出所有三元组得到对应的实体,去掉实体中的停用词和不在词表内的,再去掉置信度低于1的三元组,根据VAD词典查询得到每个实体的VAD三元组得分,构成新的三元组<实体,置信度,VAD>。
- Embdedding:
对context和response中所有词得到word embedding和position embedding。对实体得到word embedding。 - Dynamic Context-Aware Affective Graph Attention
由于不同的实体对当前词的影响不同,所以采用attention的方法对当前的实体进行加权来得到所有实体的总体表示。我们可以认为,一个重要的实体是和文本具有很强的关联性,并且要有一定的情感强度。所以在attention机制中考虑了相关性和情感性两个方面。
- 相关性:对当前句子的单词进行hierarchical pooling得到句子的表示,对所有句子求均值得到当前对话的总体表示,通过计算当前的实体表示和这个的总体表示cos相似度得到实体的相关性。
$$rel_k = min-max(s_k) * abs(cos(CR(X^i), c_k))$$ - 情感性:根据单词的VAD值计算得到:
$$aff_k = min-max(||V(c_k)-1/2, A(c_k)/2||_2)$$ - 将相关性和情感性联合起来接softmax得到当前实体的attention weight,并加权求和得到实体的总体表示。
$$w_k = \lambda_k * rel_k + (1-\lambda_k) * aff_k $$
- Hierarchical Self-Attention:
将实体表示和word embedding concat作为输入,用一层transform encoder得到每个句子的表示,再输入到一层transform encoder得到当前context的表示。同样,在对response计算过程,类似于transformer 的decoder的部分。
Experiments
实验证明加入commonsense是十分有效的。对于每部分的参数和model analysis的实验也很充足。