
 by Mikito
by Mikito
【论文阅读】Multi-Task Learning with Multi-View Attention for Answer Selection and Knowledge Base Question Answering (AAAI 2019)
其实我不怎么了解QA方向的东西,但是下面的工作可能要向multi-task方向扩展,而且这方面我也不是很了解。组里一个做QA的师兄就发了他看到的一篇论文给我,说可能对我有一定的借鉴意义。
Basic Information
- Title: Multi-Task Learning with Multi-View Attention for Answer Selection and Knowledge Base Question Answering
- Authors: Yang Deng, Yuexiang Xie, Yaliang Li, Min Yang, Nan Du, Wei Fan, Kai Lei, Ying Shen
- Institution: ICNLAB, Tencent Medical AI Lab
- Conference/Journal: AAAI 2019
- Cite: Deng Y, Xie Y, Li Y, et al. Multi-Task Learning with Multi-View Attention for Answer Selection and Knowledge Base Question Answering[J]. arXiv preprint arXiv:1812.02354, 2018.
Task & Contributions
这篇文章针对QA中的两个问题answer selection和knowledge base question answering的两个任务,提出了一个multi-task的模型。同时,为了加强tasks之间的联系,使用了一种multi-view attention机制。这篇论文的创新点如下:
- 提出了一个multi-task的模型。由于AS与KBQA的输入输出可以规范化成相同的形式,而且输出都是ranking,所以模型具有相似性。另外,AS的可以利用KBQA中的knowledge base information,KBQA可以用AS中的contextual information,所以这两个task之间具有一定的关联性,可以benefit from each other。
- 在multi-task模型的task-specific层中引入了multi-view attention机制,使得各个task之间可以互相交互。
- 实验证明了结果的有效性。
Method
Problem definition
AS和KBQA的输入都是给定一个问题,AS是在给定结果中选择正确的一个,KBQA是在知识库中找到结果。两个问题的输入如下表所示:

每个QA pair都可以被规范成上面的形式:一个Question和一个Answer,每个Question/Answer都可以被分为word sqeuence和knowledge sequence两个部分。输出是一个ranking。信息的具体抽取方法论文中都有,此处不提。
Multi-task
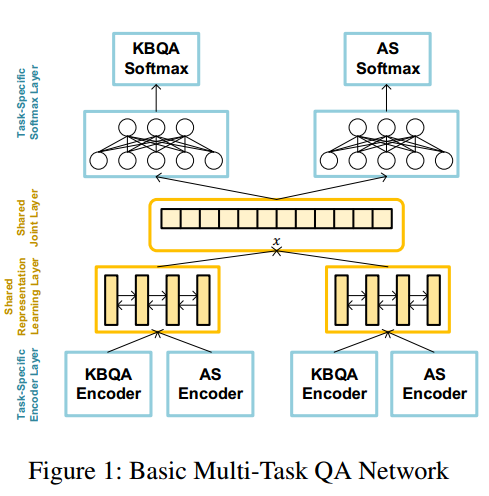
一般的multi-task模型如图所示。每个task有一个task-specific encoder。这篇论文对AS和KBQA的encoder结构相同,但是编码器中的参数不共享。对word sequence用BI-LSRM编码,对knowledge用CNN进行特征提取。然后是一个shared representation learning layer,这个模型好像是将输入同时输入到不同的encoder(输入的形式规范成相同的),然后将得到的表示用一个BiLSTM进行融合。最后全连接然后接一个softmax得到最终的输出。不同task之间有一个joint learning loss。
由于不同的task关注的点不同,提取得到的信息也会有所区别,所以这个模型适用于multi-task中输入输出都相似的模型。
Multi-view Attention
为了进一步加强不同task之间的交互,论文中提出了一个multi-view attention机制,如下图。
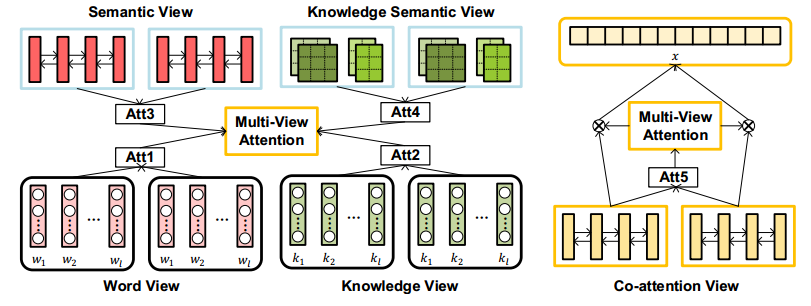
- Word view:计算Answer对Question的word sequence embedding的影响,从而得到Q的word sequence的attention。
- Knowledge view:计算Answer对Question的knowledge sequence embedding的影响,从而得到Q的knowledge sequence的attention。
- Semantic view:计算Answer/Question的word sequence feature的attention。
- Knowledge semantic view:计算Answer/Question的knowledge sequence feature的attention。
- Co-attention view:计算上面multi-task得到的Answer和Question最终表示之间的attention。
最后对求得Answer/Question的五个attention加权求和再用softmax做归一化,得到最终的结果。这些attention中的参数不同的tasks之间是共享的。
Experiments
实验结果比现在的好。
Comments
这篇论文和我想的还是有一点出入。可能是我不太了解QA这方面,我以为是关注在multi-task上。虽然这篇文章确实是再努力这一点,但是attention实在有点复杂,好像是现成的堆砌的感觉。