
 by Mikito
by Mikito
【论文阅读】Emotion Detection with Neural Personal Discrimination (EMNLP2019)
引言
这是EMNLP2019的一篇文章。
在情感分析中,通常是对于给定的一个文本,我们对它进行独立的分析和情感预测。但是根据趋同性理论,相似和关联性常常同时发生,这个理论运用到情感分析中可以认为具有相似背景的作者在表达情感时是相似的。这个和我们想要做的用户分组有一定的相似性。但是我们当时提出的是语言表达的相似性,这篇文章将用户之间的关联落到背景信息上,选取了作者的性别和位置两个属性,来得到用户之间的社会关联性。
如果选取作者的背景信息来得到文本之间的关联,这面临两个问题:(1) 如何得到用户背景相关的属性,如地区和性别;(2)怎样得到属性相关的词。针对这两个问题,本文提出了NPD模型。
对抗判别器
首先说一下对抗判别器。
这里使用的对抗判别器出自于2015年ICML的论文 Unsupervised Domain Adaptation by Backpropagation,后又加长发了2016 JMLR Domain-Adversarial Training of Neural Networks。这篇文章解决的是domain adaptation的问题,即领域适应学习,就是说源域和目标域数据分布有一定的差异性。对抗判别器通过对抗的方法使得提取出的特征具有领域无关性,使得源域和目标域数据分布对齐。domain adaptation的应用中有两个域:一个包含大量的标签信息,称为源域(source domain);另一个只有少量的甚至没有标签,但是却包含我们要预测的样本 ,称为目标域(target domain)。所以可以在源域上通过一般的机器学习方法来训练得到判别模型。但是由于源域和目标域上的dataset bias,这个判别模型不能直接移植到目标域。如何在尽量不损失判别模型的条件下将判别模型由源域迁移到目标域,就是domain adaptation要解决的问题,也称为迁移学习(transfer learning)。关于这个问题,一般有shared-classifier假设:如果可以在源域和目标域上,学习到一个公共的特征表示空间,那么在这个特征空间上,源域特征上学到的判别模型也可以用到目标域的特征上。所以domain adaptation问题往往转换为寻找公共特征表示空间的问题,也就是学习域不变特征(domain invariant feature)。本文就是利用对抗网络的框架来学习域不变特征。
模型图如下。
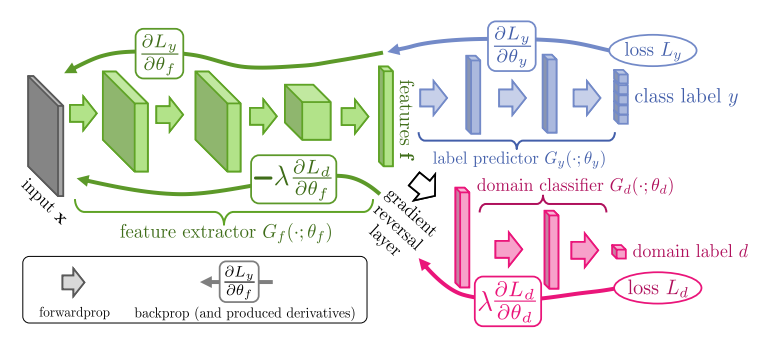
该模型分为三个部分,一个特征提取器,一个标签分类器和一个域分类器。特征提取器提取特征,比如LSTM、CNN这些,标签分类器对特征进行分类,得到正确的标签。域分类器在一般的分类器中不会出现,它对标签进行域分类,判定是源域还是目标域。
对抗体现在对于classifier损失在训练阶段两个相反的要求。具体而言:对于domain adaptation应用,我们希望网络学到的特征表示具有领域不变(domain invariant)的特征,那么就要求domain classifier不能正确进行领域分类,也就是要求domain classifier的分类损失最大;另一方面在对label classifier训练时,我们肯定要求分类器能尽可能的正确分类,也就是label classifier的分类损失最小。区别于GAN的固定一个更新另一个的方法,这两个classifier是同时更新的。
方法
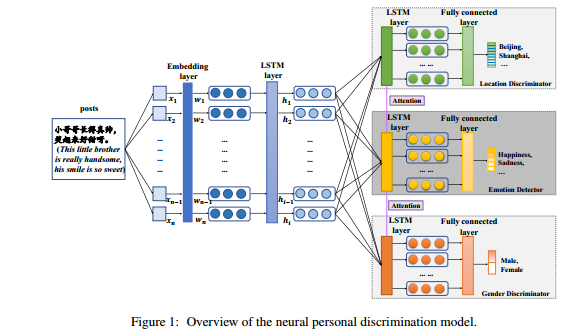
本文的模型如上图所示。
图中间就是一个基础的神经网络来做情感分析的框架,包括embedding,LSTM计算表示和MLP进行分类。
为了解决刚才所说到的问题,本文在原模型的基础上添加对抗判别器提取作者的属性(性别和位置,分别是橙色和绿色的两块),并用attention来得到attribute-aware的词。那现在的流程就变成,对于给定的一个文本, 先得到每个单词的embedding,然后用LSTM提取特征,将得到的特征传入性别和地区两个判别器中(类似于上面的domian classifier),然后进行分类得到用户的性别和地区属性。同时对于判别器中LSTM的输出用attention机制计算得到gender-aware和location-aware 的表示,并且concat得到最终表示,输入MLP中进行分类。最后优化时让gender和location的loss最大化,emotion的loss最小化。
但是这个模型和上面的不一样的在于,前面的是想让域分类器尽可能分错,来得到域无关的特征,但是这篇文章将gender和location的交叉熵损失的负号去掉,将最小化问题转为最大化问题,其实这部分对抗性不太明显,略微有点牵强。
实验
实验是在他们自己抓自己标的1w多的数据上做的。包括和SOTA方法比、model analysis、数据分析和case study。