
 by Mikito
by Mikito
【论文阅读】论文泛读系列
Emmm……我在周报没能每周完成的情况下又开了新的专题,关于论文阅读的,一般应该是有一篇精读,几篇泛读。其实我有一个进行文献管理的软件Mendeley,还是挺好用的,在此做一下安利。
Sentence-State LSTM for Text Representation
简介
这是我选的这周组会讲的论文,所以读的会比较详细一点。这篇论文的基本信息如下:
- 标题:Sentence-State LSTM for Text Representation
- 作者:Zhang Yue, Liu Qi, Song Linfeng
- 论文地址:http://arxiv.org/abs/1805.02474
- 代码地址:https://github.com/leuchine/S-LSTM
LSTM或者BiLSTM是在自然语言处理中很常用的方法。但是LSTM一个很明显的的特征,就是它的序列性,每一个细胞输出状态的计算都用到上一个细胞的信息(细胞状态和输出状态)。这个特性使得LSTM在文本的应用中可以得到之前的语义信息,具有一定的语义关联性。除了单向LSTM,为了得到下文对上文的影响,所以也有人提出了BiLSTM,即双向LSTM,将原来的LSTM倒过来再算一次。但是这两种LSTM都是序列性的,这意味着上下文之间的语义关联会随着状态的传递不断地减弱,对长文本不友好,而且计算是线性的,通常需要一定的时间。
在长文本方面,很多人提出引入attention机制,现在attention有很多种了,比如hierarchical attention。这篇文章关注于LSTM本身的属性,提出了Sentence-state LSTM,简称为S-L STM。在每个recurrent step,也就是我们说的细胞,将整个句子传入,而不是传入某一个单词,并对LSTM的门进行简单的修改,计算得到句子的局部特征(每个单词的输出状态)和整体特征(句子的整体状态),可以增加单词之间的语义关联性。相较于LSTM顺序的特性,S-LSTM中每个recurrent step中每个单词计算可以是并行的,而且recurrent step的数量与句子的长度无关,而是通过实验结果确定,一般在3-6之间。这不仅可以提高计算的正确性,还可以提高计算的效率。
算法
这是这个算法的框架图:
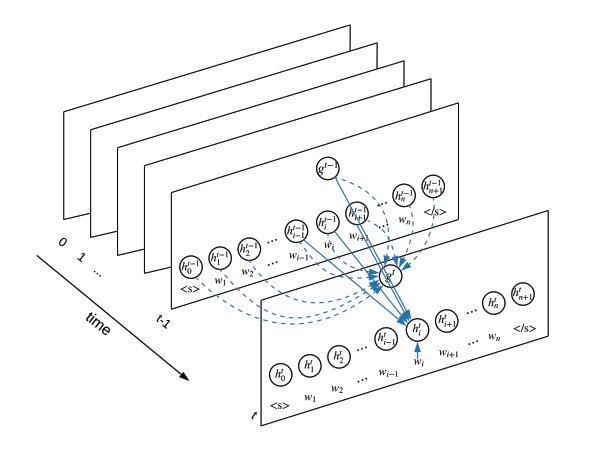
从这张图像中我们可以看出,S-LSTM与原先的LSTM还是有很大的区别的。
首先来看它的细胞(recurrent step),每个t时刻对应的就是一个细胞,而不是一个layer。在原来的LSTM中,我们一个细胞的传入是一个单词的词向量等特征,但是这里将整个句子中的每个单词都传入了,还传入了一个句子对应的一个总体状态。在对这个句子中间的第$i$个单词状态的计算过程中,都用到了上一个时刻第$i-1$、$i$、$i+1$个单词相应的信息。
具体细胞的结构可以看下面两张图。
这是一张LSTM细胞的结构图,这个在网上有很多介绍了,如果不懂可以自己看看。这里贴一个参考链接:https://blog.csdn.net/gzj_1101/article/details/79376798。
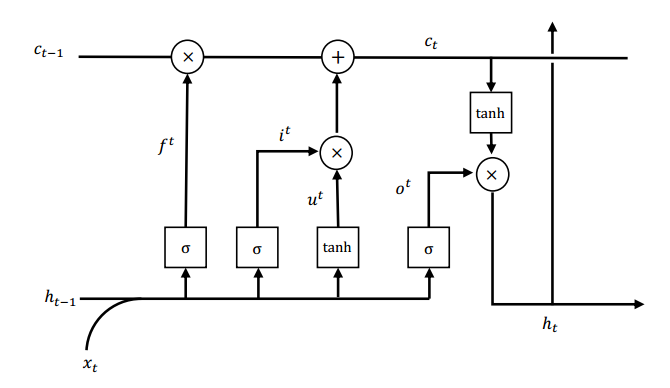
从图中我们可以看出大概有遗忘门、输入门和输出门三个部分,输入的信息就是细胞前一个的状态$c_{t-1}$和当前的单词$x_i$。
这是S-LSTM细胞中某一个单词求解的结构示意图,这并不是它的一个细胞,只是其中的一个部分。
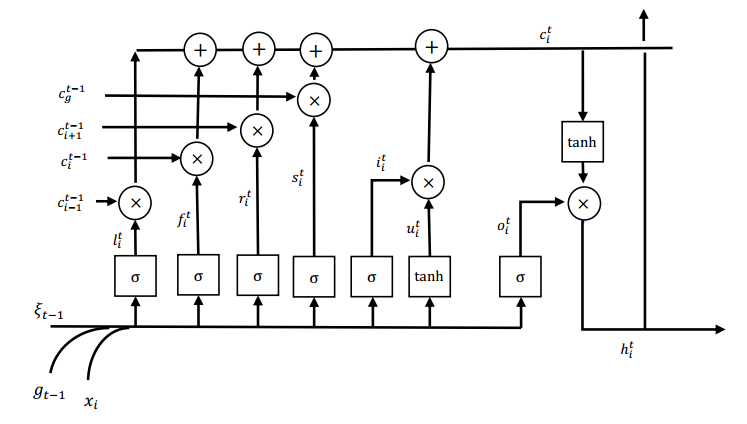
从这个图中我们可以看出,明显这个的输入参数就变多了,而且输入的$t-1$时候的输出状态也变成了一个联合状态。因为输入参数的状态变多,所以也相应添加了很多遗忘门的部分。
至于对句子状态$g^t$的求解,也是一个类似于LSTM的结构,只不过只有遗忘门和输出门的部分。
优点
这个算法是受到图思想的启发。每个细胞中单词状态的计算都利用了前后单词在上一步的状态,所以语义关联可以一步步扩展开。
另外每个细胞中单词的输出计算是互不相关的,所以可以并行计算。其次,在原来的LSTM中,$t$值的选取与句子的长短有关,但是S-LSTM中,$t$值的选取与句子长度无关,,完全可以通过实验的结果设定。所以可以大大提高计算的效率。
实验
在分类和序列标注两个方面进行了多组实验。实验结果总体正确率有了略微提升,但是性能有了很大的提高。
A Hierarchical Neural Attention-based Text Classifier
本文提出了一个新的基于Attention的分层分类器。
虽然文本->句子->单词也是一种层级结构,但是本文提出的是类似于生物类别上的大分类(taxonomy)到详细分类(class)的层级结构,所以如果要用这种的话,我们也许需要在情感分类的类别上提取出更大的类别,如sentiment分类,但是情感的正负极性也不好单一给定。或者想想能不能把这个层级结构套到文本上。
Improving Multi-label Emotion Classification via Sentiment Classification with Dual Attention Transfer Network
这篇论文提出了一种基于迁移学习(transfer learning)的方法,将原来的sentiment analysis进一步迁移到emotion detection上。
该算法提出了两种迁移模型的结构:
- SP(shared-private)模型:一个提取shared sentiment features的shared LSTM layer(对sentiment和emotion),一个提取specific emotion features的target-specific LSTM layer(只对emotion)。
- DATN(Dual Attention Transfer Network):因为SP模型只能得到粗粒度的感情,对于更细的情感词无法准确的捕捉到,所以在原来SP模型的基础上添加了一个双重(其实只有sentiment指向emotion)attention机制。